Few people think of RTL design as a form of object oriented programming, but inherently it is. In testbench, you can access variables across module hierarchy but in RTL or synthesizable logic, you can’t. So, that makes all the variables and methods inside a module local. You have to deal with the module only through its interface i.e. the I/O ports. So, the hardware structure already draws a clear division between implementation and interface; that is, only the interface is exposed to the users and not the implementation. This is the encapsulation principle, one of the most important corner stones of Computer Engineering.
You would think that this simple rule would make RTL design pretty clean and straightforward. In reality though, that’s often not the case. It still does not prevent people from coming up with bad designs. I have come across a lot of designs with bad partitioning, for example, designs with signals flying across multiple modules where they could have been more contained, designs with I/Os that are vague in their functionality or have names that are totally unrelated to their functionality, etc.
Generally, we partition a design into several functional units in order to:
- Divide and conquer
- Contain complexity
- Divide domains e.g. clock domain, power domain, etc.
- Code reuse and organization
It is important to note that these are just general guidelines. It doesn’t mean that finer partitioning is better or worse. It also doesn’t mean that there is only one way to do it right. Two designers may come up with two different partitioning and they both may be good. The goal really is to have a design that is easier to understand, to debug, and to maintain.
Contain that Nasty Complexity
Complex functionality does not need to be translated to complex implementation. Try to break it down and contain them. The more complex something is, the more crucial it is to break it down. It sounds like a common sense but unless that is actually one of the goals early on, it’s easy to slide into a complex implementation.
One of the designs I was involved with was a custom digital signal processor. It had a custom instruction set with a typical pipelined processing path i.e. instruction fetch, instruction decode, and execute. The original designer partitioned the controller into 2 modules: instruction decode (ID) and program controller (PC). It sounded reasonable, right? What could go wrong? Well, it turned out we had a cross dependency situation where the ID was depending on the PC to get the next instruction and the PC was depending on the ID to figure out the address of the next instruction. The designer was using the ID to generate some control signals for the PC. That extends the concern of figuring out the next address into the ID. On top of that, the next address logic was a complex control logic as it needed to support branching and looping. All of that was mixed inside the two modules without clear logical partitioning.
The designer left after the first generation was completed. The second generation called for additional features and a timing change. The team attempted to modify and fix the bugs but it went in a circle, a bug fixed followed by another bug found. Finally I was assigned to take over and fix the design. Rather than patching, I decided to do a major overhaul by re-partitioning it. First, I moved all the complexity of figuring out the next address totally into the PC module. The ID would then only send out high-level decoded instructions. Next I partitioned the PC into two sub-modules: one responsible for branching and another for looping. The output of the two sub-modules were then combined at the PC’s top level to generate the final address. This made timing slightly worse but it simplified the functionality greatly. It took me two weeks to re-do and re-verify the design but it was well worth it. The design was simpler and easier to fix when bugs were found. Fixing looping no longer affected branching, and vise versa.
 Complexity Creep
Complexity Creep
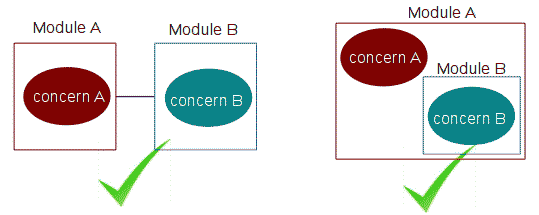 Complexity Containment
Complexity Containment